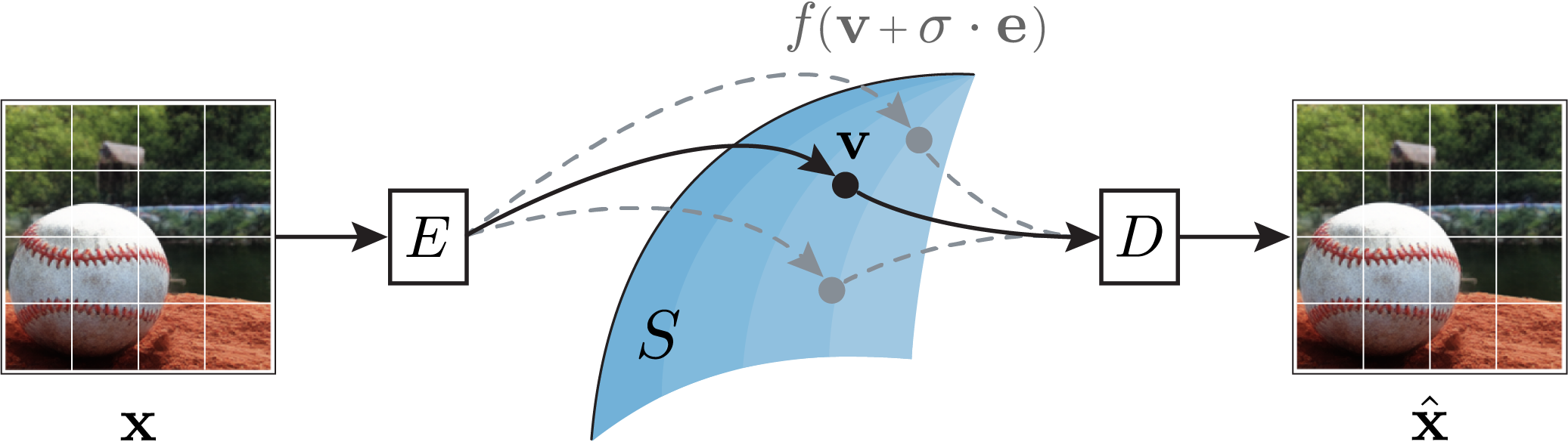
As we move through learned latent space, our model exhibits fast/sudden transitions
between image classes rather than producing ``hybrid'' images that unrealistically merge properties of
difference object types. For example, starting with the bottom-left image of a cheetah, we observe a
sudden transition from cheetah to cat as we move vertically, and from cheetah to dog as we move
horizontally. The model does not linger in a half-cheetah/half-dog state that is absent in the
training data.
These fast-transitions are necessary for a model to reliably convert random samples from the sphere
into
realistic images, as it makes the probability of observing a hybrid image small.
This important property of the sphere encoder differentiates it from other latent models. GANs, for
example, tend to exhibit slow transitions, resulting in frequent production of hybrid or distorted
objects, e.g., Figure 8 and 9 in BigGAN.